
I write my notes as I go along, but sometimes it takes me a bit to get it into a blogable format. This week took a little longer because I had to wait for Armans walkthrough. I got super close to the answer for part 3, but unfortunately missed out on the 100 points.
We’re back looking at EML files to help assist validating a story and identifying forgery, and get to play with an interesting technique!
If you'd like to play along, the challenge has been archived here
Question 1
You have been asked to examine the attached email message. The apparent author of the message, Vivian Alyse, claims that she did send an email while she was at a conference, but that the contents of the message were manipulated by the outside recipient. The recipient claims that the attached message is legitimate.
Based on the information available to you, do you believe the message is more likely to be legitimate or fake?
Enter L for legitimate, F for fake. More to come based on your answer.SHA-256: FD40B562E25B40B62D7AC06AAE84 D7B973F380A4306B1C73DC5C065B2B9540B3
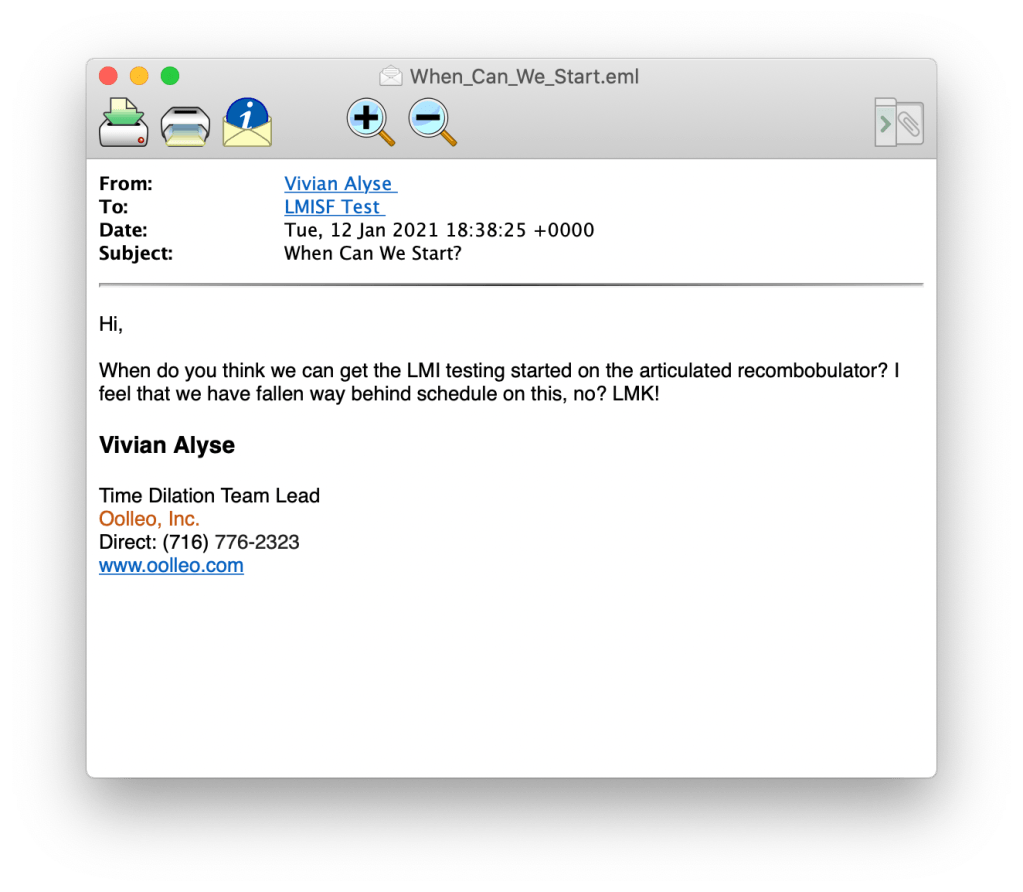
Initial observations show that this email is an email sent from Vivian to LMISF Test at Tue, 12 Jan 2021 18:38:25 +0000. There are no attachments. Not unexpectedly the email is presented in HTML.
I had a quick look at the HTML and Text components and saw that they matched. Next I thought to use the DKIM and ARC signatures to validate. I found this article quite helpful and include these two quotes:
“If the command comes back saying arc verification: cv=b’pass’ success (for ARC) or signature ok (for DKIM) then we know the message is the same as sent or received, as the case may be. If the response is “signature verification failed” or “Message is not ARC signed,” we don’t know if the email’s been tampered with or not. (Seriously — you can’t conclude that it has been tampered with. You just don’t know.)”
Jeremy B. Merrill
“While a validated DKIM signature guarantees that you have the same email that was sent; a validated ARC signature can guarantee that you have the same email that was received by the receiving server.”
Running the email through DKIMPY’s DKIM and ARC validation scripts I got DKIM failed, and ARC success.
A failure on the DKIM side may suggest that manipulation has taken place after the file was received, but it can also be legitimate manipulation – for example adding a footer or appending something to the subject. It could also mean that DKIM hasn’t been setup, but I didn’t really explore all the ins and outs of the DKIM component.
A passing ARC signature says that the email that was received, matches the email that you have; Suggesting that the email hasn’t been manipulated. Because of the ARC verification I put that the email is legitimate, which was correct. I didn’t go through email with a fine tooth comb though so this was a bit more of a gamble than it could have been (watch Arman’s walk through to see breakdown of everything!)
Question 2
Congrats on solving that mystery!
Oolleo has a company policy that requires employees to use a VPN to access the internet while at conferences and hotels. Based on the email you examined in Part 1, does it look like Vivian Alyse complied with that company policy? Enter Y for Yes, N for No.
When looking at the previous email we can see the X-Originating-IP was included.
This IP is: 103.208.220.195
I went to VirusTotal first which indicated it could be associated with ProtonVPN. Then I just googled the IP and found this link: The first line being: “103.208.220.195 is part of Proton VPN”
Therefore the answer is Yes, she complied with company policy.
Question 3
You are being asked to examine another email from an Oolleo employee to an outside address. This time, there are concerns that parts of the message body were altered after the message had been sent.
Based on the information available to you, body text represented by which lines are more likely to have been altered than not? Use only the line numbers 120 through 142 in the attached message to reference lines of body text.
Enter the list of line numbers separated by spaces. For example, if you believe body text represented by lines 139 and 140 were altered, enter the following: 139 140
SHA-256: 68280478B88C4AFC52CF4BBB21928D22 D5905C95FF7751E8D90A65896C816568
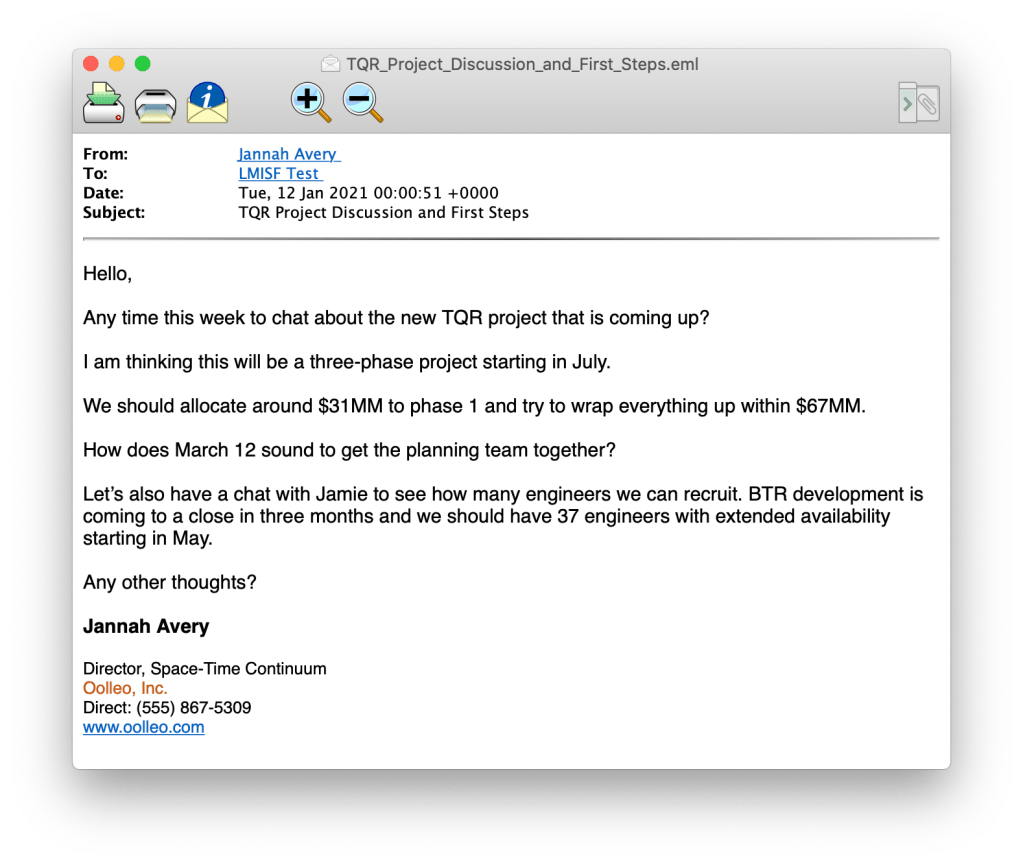
This question was particularly frustrating, because I knew the techniques I needed to chain together (after getting it wrong the first time), but I couldn’t quite figure out which line I missed (or added in erroneously).
When an email has both HTML and plain text components you can compare the two and identify whether there is a discrepancy. It would be great if tools could do this for us, but where’s the fun in that.
The first change we can see is identified really quickly because it’s a completely different word.

My next problem arose because the manipulation that took place was not as obvious. Whoever had modified the rest of the file had changed both the plain text and HTML components. That wasn’t helpful!
Looking at the block of text within the HTML component we can see that it’s quote-printable encoded, which means that we have to look up another RFC! This says that the maximum line size should be 76 characters. As such if we take a look at the HTML component and see any rows that go longer than 76 characters that’s a clear sign of manipulation. Now because of this, I know that there are two lines definitely modified, however that was also incorrect.
In the image below I’ve highlighted both of the lines that are deemed to have been manipulated as a minimum (excluding the changed word). As you can see, it’s not a straight line of = signs. The part that slighly threw me here is that I didn’t think that it’s a requirement for it to finish in an equal sign, but then if the mail application is cutting off a word it probably would put the = in there to wrap around. We can see on line 229 for example that the line ends well short, and has no reason to add an = at the end.
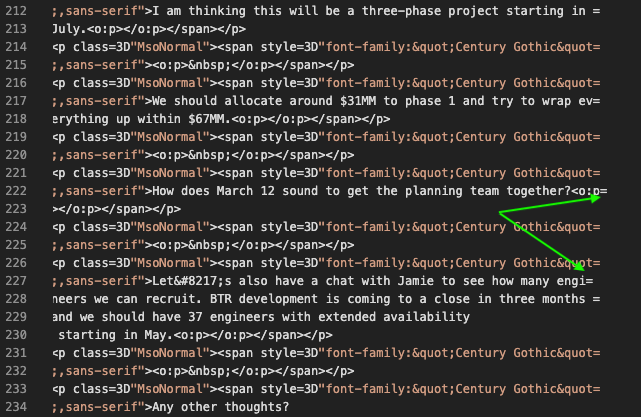
Now we have to map these two lines back to our text component, as that was requested in the question.
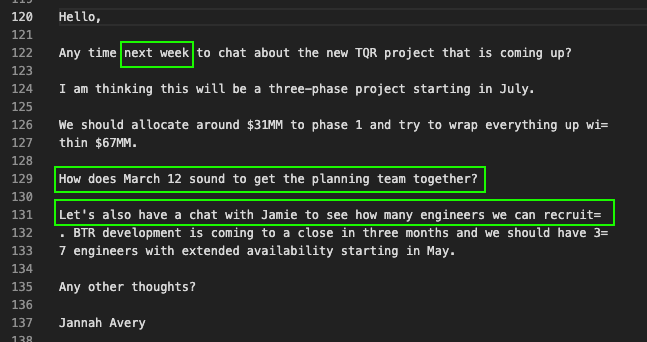
Looking at this again, it’s pretty obvious that line 131 was manipulated in some way. It’s 1 character shorter than it should be as well, suggesting that something was manipulated in both line 131 and line 227 (HTML component).
I’m not entirely sure what exactly I submitted outside of submitting 122, 129, 133 which wasn’t correct. Clearly something was up with the large paragraph, but I thought it had to do with the shortness of the bottom line. This is mainly because there was both a number and a month in there and I thought that they would be more likely to be manipulated I guess.
Overall this last question had me pulling my hair out, but was very interesting to go through. Clearly you’d have major questions after finding the first part of the manipulation, but it’s pretty interesting to be able to highlight multiple places that someone may have modified an email.
I’ve got my notes for week 6 done, so hopefully I can find some time to write that one up. And then week 7, eventually. Time is running away.

[…] ThinkDFIRMetaspike CTF – Week 5 – “Spot the DFIRence” […]
LikeLike