
Welcome to 2023!
Turns out I didn’t post on here as much as I should have last year. Logging in this morning I can see I posted twice, whoops. Let’s change that with some validation research into INDX records, particularly in relation to the timestamps that are stored in INDX entries.
I’ve been putting together my talk for the upcoming Magnet Virtual Summit, and my talk is about carving out forensic artefacts from an encrypted VHDX file that I had during an ransomware investigation last year. During my investigation I had to use a variety of tools to piece together a timeline of activity from a blob of partially encrypted data, which was an interesting process.
One of the artefacts that I used was INDX records, which has lead me to play with a number of different tools and processes. The point of this post relates to the timestamps that you can find when parsing $I30 entries.
Without going into too much detail, because Willi (slides) and Brian have done a much better job; INDX records are stored (or referenced) in the MFT entries for directories within a combination of the INDX_Root and INDX_Allocation attributes and the $Bitmap NTFS file. Tools like FTK Imager will expose this data to you as $I30 files, or showing that an entry exists in the $I30 that isn’t in the MFT. Selecting an item in FTK Imager will even show you the data recorded in the INDX entry for the given item!
What’s cool is that these items contain a known structure, so we can use tools like IndxCarver by Joachim Schicht to examine our encrypted volume and go looking for entries in unallocated space. Now it’s important to note that for my volume, these weren’t necessarily unallocated entries – because the encryption had hit the beginning of the VHDX file the headers of the disk were gone, and I don’t think there’s an easy way to piece that back together. Instead I relied on carving what I knew I could carve and put things back!
Here’s a list of tools that you can use to extract and/or parse $I30 entries:
- MFTECMD
- Bulk_Extractor and Bulk_Extractor-rec
- INDXRipper
- INDXParse (version 1 and 2)
- dfir_ntfs
- IndxCarver and Indx2Csv
They all have strengths and weaknesses and operate slightly differently. I haven’t yet done a comparison about how well they perform, however I would want to use IndxCarver or Bulk Extactor in a ransomware investigation or to rip out the data from unallocated. As far as I’m aware the other tools don’t go hunting there. INDXRipper is the next best thing in which it will run across an entire mount point or image. I have not yet tested out DFIR NTFS but Maxim is a wealth of knowledge on file systems so I expect good things.
Now, onto the point of this post!
While doing some reading about these structures to get a better handle on things, I observed that often people would write that the INDX entries would contain a FILE_NAME record. A FILE_NAME record in an MFT entry contains a series of timestamps, which are updated slightly differently to the STANDARD_INFORMATION (0x10) attributes. When revising the material found in the FOR508 Advanced Incident Response, Threat Hunting, and Digital Forensics course by SANS there is a note that states that even though the entry says it should contain the timestamps found in entries FILE_NAME (0x30) attribute, it actually contains the timestamps found in the entries STANDARD_INFORMATION attribute. Well that’s exciting – something to test!
So how can I test this:
The simplest way that I could come up with was to grab a test image and compare the timestamps; for this I chose Andrew Rathbun’s Anti-Forensics VHDX, and FTK Imager – because it will show me the file system and $I30 timestamps in one place.
The reason that I chose the Anti-Forensics VHDX is because it was more likely to contain entries with more obviously differing STANDARD_INFORMATION and FILE_NAME timestamps.
From here it’s just a comparison – what are the 0x10 and 0x30 timestamps and what are the $I30 timestamps?
$STANDARD_INFORMATION


$FILE_NAME (MAC)

$I30->$FILE_NAME (MAC)
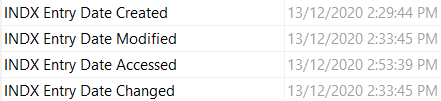
In this example we can see that the $I30->FILE_NAME timestamps align with the STANDARD_INFORMATION timestamps and not the $FILE_NAME timestamps.
Interestingly there was a recovered $I30 record that had different timestamps, that align with the FILE_NAME timestamps
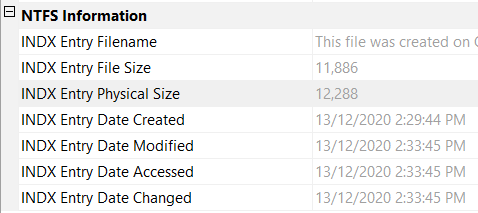
However, other items that I selected had the STANDARD_INFORMATION attributes showing the same timestamps as in the $I30.
I did also ask Maxim (in a Github Issue on a semi-related topic no less) about how the timestamps should work and this is what he had to say:

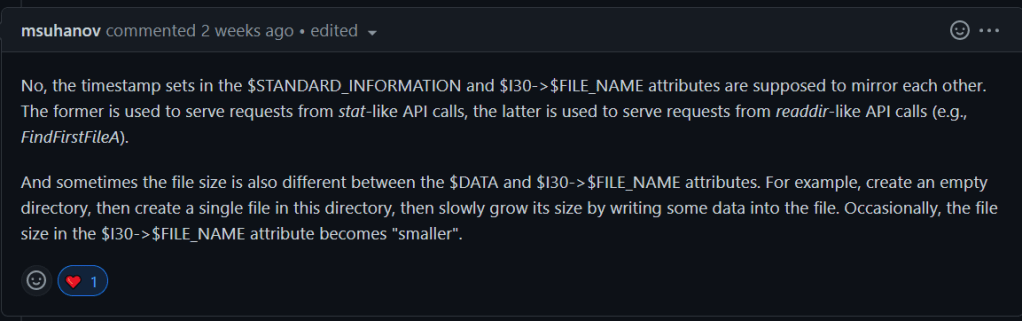
This would mean that while typically the data should match, sometimes the file size and the ‘last access’ timestamp will be different in the $I30 timestamp.

[…] ThinkDFIRTimestamps in INDX Entries […]
LikeLike